Zasady działania systemu kontroli wersji GIT
Pisząc kod (zarówno jako programista, jak i tester automatyzacyjny) olbrzymim wyzwaniem jest kontrola jego wersji, jak i łączenia wielu zmian, wytworzonych przez wiele osób, dokonanych na wielu plikach w różnym czasie, w jedną całość. Czynności te umożliwia nam GIT.
GIT to rozproszony system kontroli wersji. Aktualnie nikt już nie wyobraża sobie tworzenie wielkich projektów informatycznych bez użycia narzędzia do kontroli wersji. We współczesnym środowisku IT możemy znaleźć wiele projektów, przy których procesach wytwórczych został wykorzystany GIT. Do takich projektów należą: jądro Linuksa ( wraz z jego podprojektami), GNU Hurd, GNOME,, GIMP, Perl, Qt, Ruby on Rails, i wiele wiele innych. Ze znanych serwisów internetowych, które wykorzystywały GIT, możemy wyróżnić np. Facebook. Do przechowywania repozytoriów używamy najczęściej: Bitbucket, GitHub lub GitLab (zestawienie i porównanie tych serwisów hostingowych zostanie przedstawione w następnych podrozdziałach).
Historia powstania
GIT powstał w 2005 roku, a jego głównym przeznaczeniem było kontrolowanie wersji przy tworzeniu jądra Linuksa. Jak to się stało, że prace nad narzędziem w ogóle się rozpoczęły?
U zarania dziejów (czyli w okolicach roku 2002) do tworzenia jądra Linuksa zespół używał systemu DVCS BitKeeper. Niestety w okolicach roku 2005 nastąpiło ochłodzenie relacji pomiędzy twórcami jądra Linuksa a firmą tworzącą BitKeepera, co zaowocowało cofnięciem bezpłatnej licencji. Twórcy Linuksa (w tym przede wszystkim Linus Torvalds) postanowili, że stworzą własne narzędzie do kontroli wersji. Tempo prac było niesamowite, gdyż projekt rozpoczął się 3 kwietnia 2005 roku, a już 7 kwietnia GIT obsługiwał własny kod, natomiast 18 kwietnia zostały połączone pierwsze gałęzie, a 16 czerwca Linux 2.6.12 był hostowany przez Gita. Przez kolejne lata GIT dojrzewał, a aktualnie możemy z jego pomocą tworzyć bardzo zaawansowane projekty.
Migawki
Innowacja GIT polega na sposobie przechowywania danych. Inne systemy przechowują dane jako listę zmian na plikach. GIT natomiast traktuje dane jako zestaw migawek, które tworzone są zawsze kiedy wysyłamy commit lub zapisujemy stan projektu. Kolokwialnie mówiąc migawka to zdjęcie wszystkich plików w danym momencie. Dodatkowo GIT przechowuje referencje do niej. Olbrzymią zaletą GIT jest to, że zapisuje tylko różnice (GIT nie zapisuje ponownie plików, które nie zostały zmienione, ale referencje do poprzedniej, identycznej wersji), przez co narzędzie jest bardzo szybkie i wydajne.
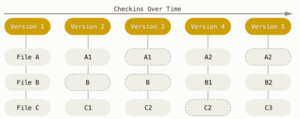 Źródło: https://git-scm.com/book/pl/v2/Pierwsze-kroki-Podstawy-Git
Źródło: https://git-scm.com/book/pl/v2/Pierwsze-kroki-Podstawy-Git
Stany GIT
Cechą charakterystyczną dla GIT są trzy stany w jakich może znajdować się plik: zatwierdzony, zmodyfikowany, śledzony. Stan zatwierdzony oznacza, że dane zostały zachowane w lokalnej bazie danych i są bezpieczne. Stan zmodyfikowany oznacza, że została wprowadzona zmiana do pliku (np. napisaliśmy linijkę kodu), ale zmiany nadal nie zostały wprowadzone do bazy danych. Natomiast stan śledzony oznacza, że przy następnej operacji commit zmodyfikowany plik zostanie zatwierdzony.
Podstawowy scenariusz pracy z GIT
Możemy wyróżnić podstawowy przykładowy scenariusz pracy z GIT.
- Klonujemy repozytorium na nasz lokalny sprzęt (jeśli repozytorium nie istnieje to je tworzymy, a potem klonujemy). Robimy to tylko raz, rozpoczynając pracę.
- Wprowadzamy zmiany do pliku w katalogu roboczym, czyli wprowadzamy modyfikację.
- Oznaczamy zmienione pliki jako śledzone, w przechowalni pojawia się ich migawka (bieżący stan)
- Dokonujemy operacji commit.
Artykuł będzie aktualizowany po zebraniu pytań z aktualnie przeprowadzanych warsztatów GIT.
Może Ci się spodobać

Dzień 17 – książki i partnerstwa oraz nowe inicjatywy dla dzieci!

Nabór na V edycję Cherry-IT: Mentoring!
